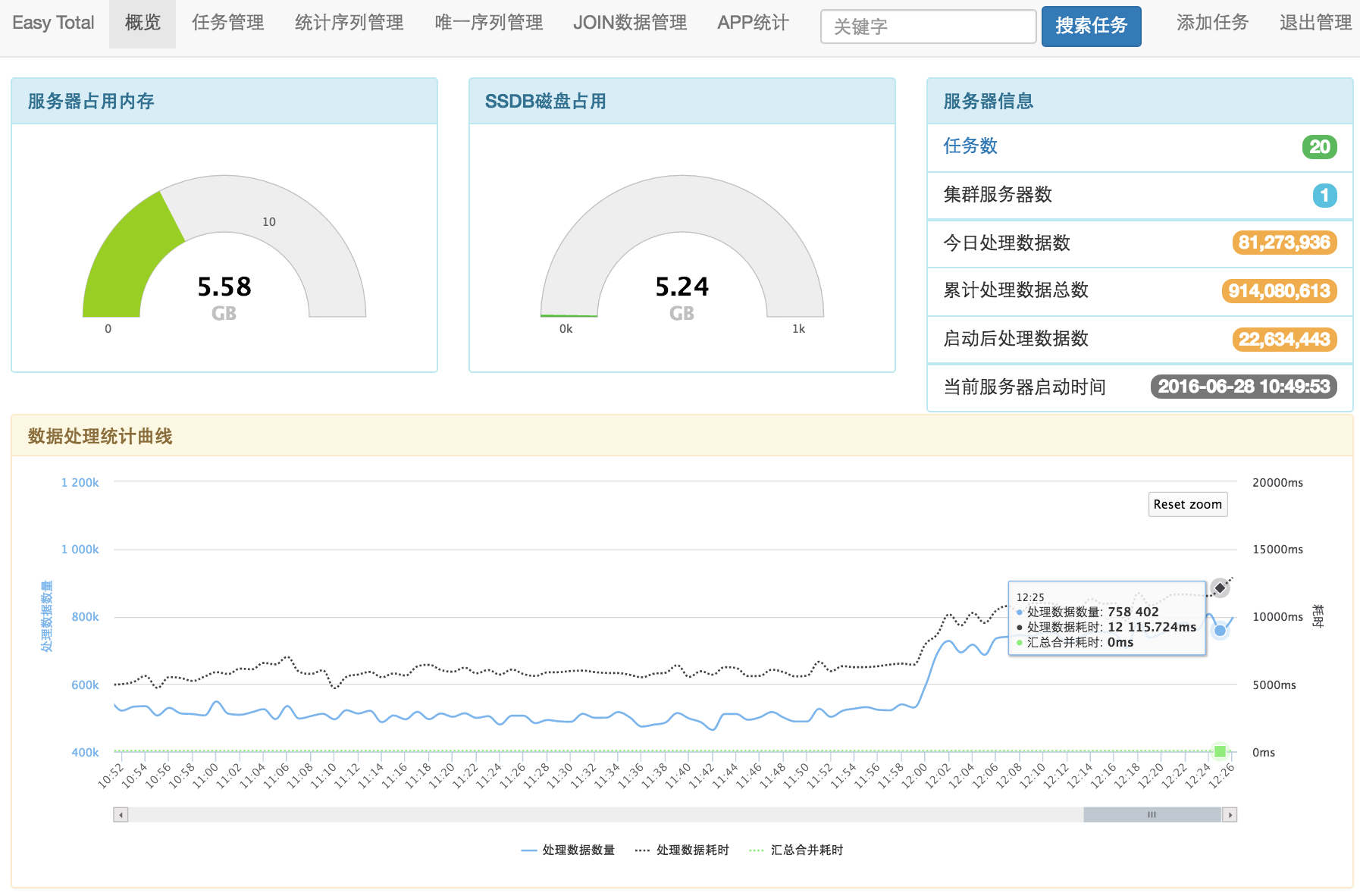
因为我们公司游戏的日志越来越多,普通的数据光插入数据就会让数据库挂掉,后来我们用 Hadoop 集群来处理日志,但是问题是需要越来越多的服务器,为了解决这个问题,用了半年时间开发了一个简单好用的实时统计服务器:EasyTotal。此服务还在测试,感兴趣的同学可以去点赞或贡献代码,项目地址 https://github.com/xindong/easy-total。在我们线上测试环境(监听了20多条统计的SQL语句)单机每分钟处理300万+的日志量cpu负载在 3 – 5之间,可持续处理1000万/分钟的日志量,峰值可达1300万/分钟,这样的性能堪称无敌,因为这样的数据光插入 10 台机器组成的 Elasticsearch 集群用不了多久集群就要挂了。
下面是项目介绍:
EasyTotal 是一个通过监听预先添加好的SQL统计查询语句,对汇入的数据进行实时统计处理后不间断的将统计结果导出的服务解决方案,它解决了日志数据量非常巨大的情况下,数据库无法承载巨大的插入和查询请求的问题,并且可以满足业务统计的需求。程序的网络层是采用c写的swoole扩展进行处理,具有极高的性能,网络处理能力和 nginx 相当,处理数据模块采用 php 开发则可以方便团队根据自己的需求进行二次开发。
支持常用的运算统计功能,比如 count, sum, max, min, avg, first, last, dist,支持 group by、where 等,后续将会增加 join 的功能。
特点:
- 实时处理,定时汇出统计结果;
- 对巨大的日志量进行清洗汇总成1条或多条输出,可以成万倍的缩小数据体量,可在汇总结果中进行二次统计;
- 特别适用于对大量log的汇入统计,免去了先入库再统计这种传统方式对系统造成的负担;
- 分布式水平扩展,支持随时增删统计服务器;
- 不需要特别的技术、使用简单;
- 可以二次开发;
使用场景
当需要对业务数据进行统计分析时,传统的做法是把数据或日志导入到数据库后进行统计,但是随着数据量的增长,数据库压力越来越大甚至插入数据都成问题更不用说是进行数据统计了,此时只能对数据进行分库、分片等处理或者是用 hadoop、spark 等离线统计,然后就需要分布式架构,这在技术角度上来说是可行的做法,但这带来的问题就是:
- 需要很多服务器,增加巨额托管费用;
- 需要能够hold住这些服务器和技术的高级开发及运维人员;
- 架构调整导致的研发难度和周期增加;
EasyTotal 正是为了解决这些问题而诞生,可以用极少的服务器以及简单的技术就能处理巨大的数据并满足业务统计的需求,对你来说一切都是那么的easy。
上两张管理界面: